 0dayhub
0dayhub# 5.9. 预测目标 (`y`) 的转换
校验者: @FontTian @numpy 翻译者: @程威 本章要介绍的这些变换器不是被用于特征的,而是只被用于变换监督学习的目标。 如果你希望变换预测目标以进行学习,但是在原始空间中评估模...
校验者: @FontTian @numpy 翻译者: @程威 本章要介绍的这些变换器不是被用于特征的,而是只被用于变换监督学习的目标。 如果你希望变换预测目标以进行学习,但是在原始空间中评估模...

校验者: @不吃曲奇的趣多多 @A @火星 @Trembleguy @Loopy 翻译者: @cowboy @peels ...

7.1. 大规模计算的策略: 更大量的数据 校验者: @文谊 翻译者: @ゞFingヤ 对于一些应用程序,需要被处理的样本数量,特征数量(或两者)和/或速度这些对传统的方法而言非常具有挑战性。在这些情况下,s...

校验者: @尔了个达 @维 @子浪 @小瑶 @Loopy @qinhanmin2014 翻译者: @Damon @Leon晋 支持向量机 (SV...
使用 scikit-learn 介绍机器学习 机器学习:问题设置 加载示例数据集 学习和预测 模型持久化 规定 关于科学数据处理的统计学习教程 机器学习: scikit-learn 中的设置以及预估对象 数据集 预估对象 监督学习:从高维观...

校验者: @小瑶 @hlxstc @BWM-蜜蜂 @小瑶 @Loopy 翻译者: @李昊伟 @… 内容提要 在本节中,我们介绍一些在使用 sciki...
校验者: 待校验 翻译者: @Loopy 统计学习 随着科学实验数据集规模的快速增长,机器学习机器学习技术正变得越来越重要。它能处理的问题主要包括:建立连接不同观测值的预测函数,对观测值进行分类,或者分析未标记数据集中的结构。 本教程将探讨...
校验者: @Kyrie @片刻 翻译者: @冰块 数据集 Scikit-learn可以从一个或者多个数据集中学习信息,这些数据集合可表示为2维阵列,也可认为是一个列表。列表的第一个维度代表 样...
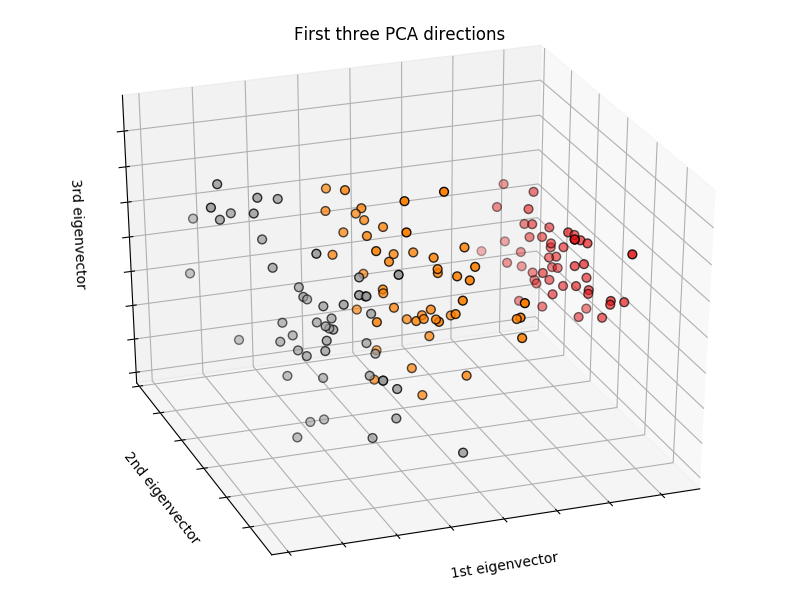
校验者: @Kyrie @片刻 @Loopy 翻译者: @森系 监督学习解决的问题 监督学习 在于学习两个数据集的联系:观察数据 X 和我们正在尝试预测的额外变量 y (通常称“目标”或“标签...

校验者: @片刻 翻译者: @森系 分数和交叉验证分数 如我们所见,每一个估计量都有一个可以在新数据上判定拟合质量(或预期值)的 score 方法。越大越好. >>> from sklearn i...