 0dayhub
0dayhub# 5. 数据集转换
scikit-learn 提供了一个用于转换数据集的库, 它也许会 clean(清理)(请参阅 预处理数据), reduce(减少)(请参阅 无监督降维), expand(扩展)(请参阅 内核近似)或 generate(生成)(请参阅 特征...
scikit-learn 提供了一个用于转换数据集的库, 它也许会 clean(清理)(请参阅 预处理数据), reduce(减少)(请参阅 无监督降维), expand(扩展)(请参阅 内核近似)或 generate(生成)(请参阅 特征...
校验者: @程威 @Loopy 翻译者: @Sehriff 变换器(Transformers)通常与分类器,回归器或其他的学习器组合在一起以构建复合估计器。 完成这件事的最常用工具是 Pipe...

校验者: @if only 翻译者: @片刻 模块 sklearn.feature_extraction 可用于提取符合机器学习算法支持的特征,比如文本和图片。 注意 特征特征提取与特征选择有很大的不同:前者...

校验者: @不吃曲奇的趣多多 @Loopy @qinhanmin2014 翻译者: @Counting stars 内核岭回归(Kernel ridge regression-KRR)[1] ...

校验者: @if only 翻译者: @Trembleguy sklearn.preprocessing 包提供了几个常见的实用功能和变换器类型,用来将原始特征向量更改为更适合机器学习模型的形式。 一般来说,...
校验者: @if only 待二次校验 翻译者: @Trembleguy @Loopy 因为各种各样的原因,真实世界中的许多数据集都包含缺失数据,这类数据经常被编码成空格、NaNs,或者是其他...
校验者: @程威 翻译者: @十四号 如果你的特征数量很多, 在监督步骤之前, 可以通过无监督的步骤来减少特征. 很多的 无监督学习 方法实现了一个名为 transform 的方法, 它可以用来降低维度. 下...

校验者: @FontTian @程威 翻译者: @Sehriff sklearn.random_projection 模块实现了一个简单且高效率的计算方式来减少数据维度,通过牺牲一定的精度(作...
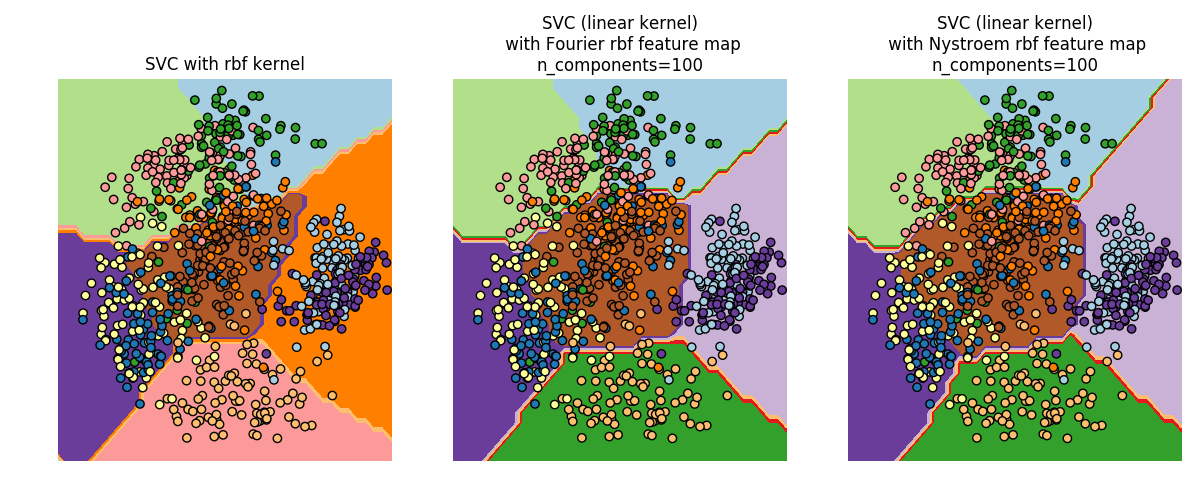
校验者: @FontTian @numpy @Loopy 翻译者: @程威 这个子模块包含与某些 kernel 对应的特征映射的函数,这个会用于例如支持向量机的算法当中(see...
校验者: @FontTian @numpy 翻译者: @程威 本章要介绍的这些变换器不是被用于特征的,而是只被用于变换监督学习的目标。 如果你希望变换预测目标以进行学习,但是在原始空间中评估模...