 0dayhub
0dayhub# 2. 无监督学习
2.1 高斯混合模型 2.1.1 高斯混合 2.1.1.1 优缺点 2.1.1.1.1 优点 2.1.1.1.2 缺点 2.1.1.2 选择经典高斯混合模型中分量的个数 2.1.1.3 估计算法期望最大化(EM) 2.1.2 变分贝叶斯高斯...
2.1 高斯混合模型 2.1.1 高斯混合 2.1.1.1 优缺点 2.1.1.1.1 优点 2.1.1.1.2 缺点 2.1.1.2 选择经典高斯混合模型中分量的个数 2.1.1.3 估计算法期望最大化(EM) 2.1.2 变分贝叶斯高斯...

校验者: @专业吹牛逼的小明 @Gladiator @Loopy @qinhanmin2014 翻译者: @瓜牛 @年纪大了反应慢了 @Hazekiah ...

校验者: @why2lyj @Shao Y. @Loopy @barrycg 翻译者: @glassy MARKDOWN_HASH923bdc0bdd7c922372eee9a98649036...

校验者: @XuJianzhi @RyanZhiNie @羊三 @Loopy @barrycg 翻译者: @XuJianzhi @羊三 ...

校验者: @花开无声 @小瑶 @Loopy @barrycg 翻译者: @小瑶 @krokyin 未标记的数据的 聚类(Clustering) 可以使用模块 sklearn.c...

校验者: @udy @barrycg 翻译者: @程威 Biclustering(双向聚类) 的实现模块是 sklearn.cluster.bicluster。 双向聚类算法对数据矩阵的行列同时进行聚类。而这...

校验者: @武器大师一个挑俩 @png 翻译者: @柠檬 @片刻 2.5.1. 主成分分析(PCA) 2.5.1.1. 准确的PCA和概率解释(Exact PCA and pr...

校验者: @李昊伟 @小瑶 @Loopy 翻译者: @柠檬 许多统计问题在某一时刻需要估计一个总体的协方差矩阵,这可以看作是对数据集散点图形状的估计。 大多数情况下,基于样本的估计(基于其属性...

校验者: @RyanZhiNie @羊三 @Loopy 翻译者: @羊三 许多应用需要能够对新观测进行判断,判断其是否与现有观测服从同一分布(即新观测为内围值),相反则被认为不服从同一分布(即...
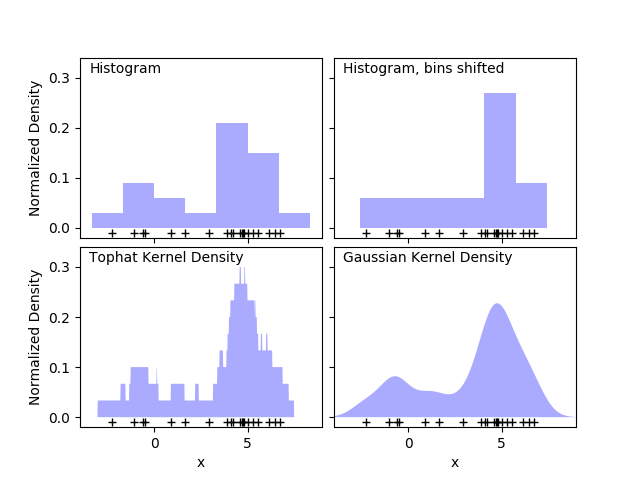
校验者: @不将就 翻译者: @Xi 密度估计在无监督学习,特征工程和数据建模之间划分了界线。一些最流行和最有用的密度估计方法是混合模型,如高斯混合( sklearn.mixture.GaussianMixt...