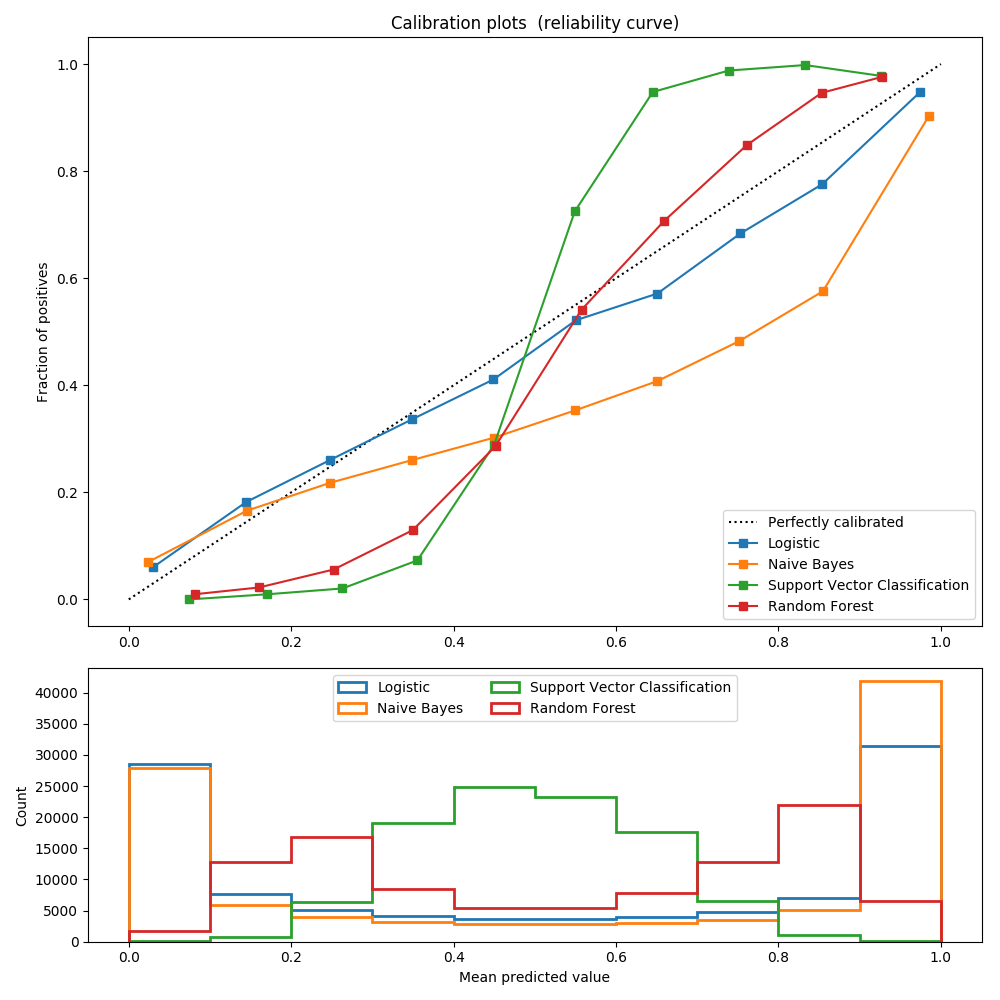
# 1.16. 概率校准
校验者: @曲晓峰 @小瑶 翻译者: @那伊抹微笑 执行分类时, 您经常希望不仅可以预测类标签, 还要获得相应标签的概率. 这个概率给你一些预测的信心. 一些模型可以给你贫乏的概率估计, 有些...
 0dayhub
0dayhub校验者: @曲晓峰 @小瑶 翻译者: @那伊抹微笑 执行分类时, 您经常希望不仅可以预测类标签, 还要获得相应标签的概率. 这个概率给你一些预测的信心. 一些模型可以给你贫乏的概率估计, 有些...

校验者: @tiantian1412 @火星 @Loopy 翻译者: @A 警告 此实现不适用于大规模数据应用。 特别是 scikit-learn 不支持 GPU。如果想要提高运行速度并使用基...
2.1 高斯混合模型 2.1.1 高斯混合 2.1.1.1 优缺点 2.1.1.1.1 优点 2.1.1.1.2 缺点 2.1.1.2 选择经典高斯混合模型中分量的个数 2.1.1.3 估计算法期望最大化(EM) 2.1.2 变分贝叶斯高斯...

校验者: @专业吹牛逼的小明 @Gladiator @Loopy @qinhanmin2014 翻译者: @瓜牛 @年纪大了反应慢了 @Hazekiah ...

校验者: @why2lyj @Shao Y. @Loopy @barrycg 翻译者: @glassy MARKDOWN_HASH923bdc0bdd7c922372eee9a98649036...

校验者: @XuJianzhi @RyanZhiNie @羊三 @Loopy @barrycg 翻译者: @XuJianzhi @羊三 ...

校验者: @花开无声 @小瑶 @Loopy @barrycg 翻译者: @小瑶 @krokyin 未标记的数据的 聚类(Clustering) 可以使用模块 sklearn.c...

校验者: @udy @barrycg 翻译者: @程威 Biclustering(双向聚类) 的实现模块是 sklearn.cluster.bicluster。 双向聚类算法对数据矩阵的行列同时进行聚类。而这...

校验者: @武器大师一个挑俩 @png 翻译者: @柠檬 @片刻 2.5.1. 主成分分析(PCA) 2.5.1.1. 准确的PCA和概率解释(Exact PCA and pr...

校验者: @李昊伟 @小瑶 @Loopy 翻译者: @柠檬 许多统计问题在某一时刻需要估计一个总体的协方差矩阵,这可以看作是对数据集散点图形状的估计。 大多数情况下,基于样本的估计(基于其属性...