 0dayhub
0dayhub
# 监督学习:从高维观察预测输出变量
校验者: @Kyrie @片刻 @Loopy 翻译者: @森系 监督学习解决的问题 监督学习 在于学习两个数据集的联系:观察数据 X 和我们正在尝试预测的额外变量 y (通常称“目标”或“标签...
校验者: @Kyrie @片刻 @Loopy 翻译者: @森系 监督学习解决的问题 监督学习 在于学习两个数据集的联系:观察数据 X 和我们正在尝试预测的额外变量 y (通常称“目标”或“标签...

校验者: @片刻 翻译者: @森系 分数和交叉验证分数 如我们所见,每一个估计量都有一个可以在新数据上判定拟合质量(或预期值)的 score 方法。越大越好. >>> from sklearn i...
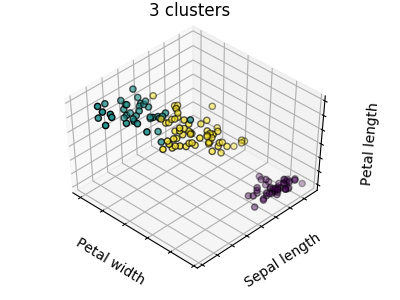
校验者: @片刻 翻译者: @X 聚类: 对样本数据进行分组 可以利用聚类解决的问题 对于 iris 数据集来说,我们知道所有样本有 3 种不同的类型,但是并不知道每一个样本是那种类型:此时我们可以尝试一个 ...

校验者: @片刻 翻译者: @X 模型管道化 我们已经知道一些模型可以做数据转换,一些模型可以用来预测变量。我们可以建立一个组合模型同时完成以上工作: import numpy as np import ma...
校验者: @片刻 翻译者: @X 项目邮件列表 如果您在使用 scikit 的过程中发现错误或者需要在说明文档中澄清的内容,可以随时通过 Mailing List 进行咨询。 机器学习从业者的 Q&A...
校验者: @NellyLuo @那伊抹微笑 @微光同尘 翻译者: @Lielei 本指南旨在一个单独实际任务中探索一些主要的 scikit-learn 工具: 分析关于 20 ...

校验者: @A @HelloSilicat @Loopy @qinhanmin2014 翻译者: @L 随机梯度下降(SGD) 是一种简单但又非常高效的方法,主要用于凸损失函数下线性分类器的判...

校验者: 翻译者: @李孟禹 通常,解决机器学习问题的最困难的部分可能是找到恰当的的评估器(estimator)。 不同的评估器更适合不同类型的数据和不同的问题。 下面的流程图是一些粗略的指导,可以让用户根据自己的数据来选择...
校验者: 翻译者: @巴黎灬メの雨季 For written tutorials, see the Tutorial section of the documentation. Scientific Python 的新手? ...
校验者: @小瑶 @Loopy 翻译者: @片刻 Note 如果你想为这个项目做出贡献,建议你 安装最新的开发版本 . 安装最新版本 Scikit-learn 要求: Python (>= 3.5), ...