 0dayhub
0dayhub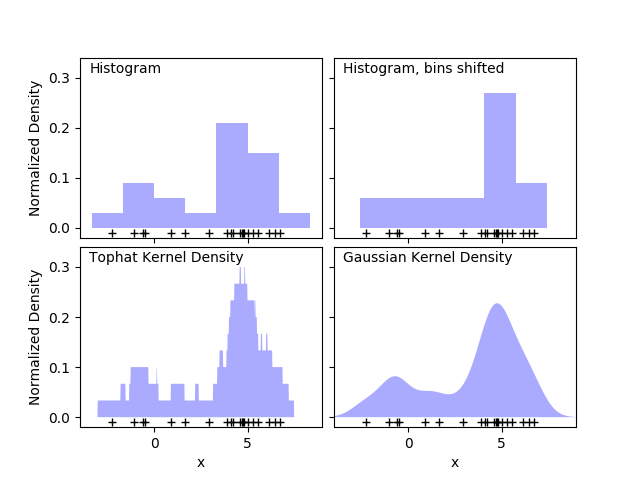
# 2.8. 密度估计
校验者: @不将就 翻译者: @Xi 密度估计在无监督学习,特征工程和数据建模之间划分了界线。一些最流行和最有用的密度估计方法是混合模型,如高斯混合( sklearn.mixture.GaussianMixt...
校验者: @不将就 翻译者: @Xi 密度估计在无监督学习,特征工程和数据建模之间划分了界线。一些最流行和最有用的密度估计方法是混合模型,如高斯混合( sklearn.mixture.GaussianMixt...

校验者: @RyanZhiNie @羊三 @Loopy 翻译者: @羊三 许多应用需要能够对新观测进行判断,判断其是否与现有观测服从同一分布(即新观测为内围值),相反则被认为不服从同一分布(即...

校验者: @不将就 @Loopy 翻译者: @夜神月 2.9.1. 限制波尔兹曼机 Restricted Boltzmann machines (RBM)(限制玻尔兹曼机)是基于概率模型的无监督非线性特征学习...
3.1 交叉验证:评估估算器的表现 3.1.1 计算交叉验证的指标 3.1.1.1 cross_validate 函数和多度量评估 3.1.1.2 通过交叉验证获取预测 3.1.2 交叉验证迭代器 3.1.2.1 交叉验证迭代器–循环遍历数...

校验者: @AnybodyHome @numpy @Loopy 翻译者: @FAME Linear Discriminant Analysis(线性判别分析)(discriminant_ana...

校验者: @想和太阳肩并肩 @樊雯 @Loopy 翻译者: @\S^R^Y/ 学习预测函数的参数,并在相同数据集上进行测试是一种错误的做法: 一个仅给出测试用例标签的模型将会获得极高的分数,但...
校验者: @想和太阳肩并肩 翻译者: @\S^R^Y/ 超参数,即不直接在估计器内学习的参数。在 scikit-learn 包中,它们作为估计器类中构造函数的参数进行传递。典型的例子有:用于支持向量分类器的 ...
校验者: @why2lyj(Snow Wang) @小瑶 翻译者: @那伊抹微笑 在训练完 scikit-learn 模型之后,最好有一种方法来将模型持久化以备将来使用,而无需重新训练。 以下...

校验者: @飓风 @小瑶 @FAME @v @Loopy 翻译者: @小瑶 @片刻 @那伊抹微笑 有 3 种不同的 API 用于...

校验者: @正版乔 @正版乔 @小瑶 翻译者: @Xi 每种估计器都有其优势和缺陷。它的泛化误差可以用偏差、方差和噪声来分解。估计值的 偏差 是不同训练集的平均误差。估计值的 ...