 0dayhub
0dayhub校验者:
@专业吹牛逼的小明
@Gladiator
@Loopy
@qinhanmin2014
翻译者:
@瓜牛
@年纪大了反应慢了
@Hazekiah
@BWM-蜜蜂
本章主要讲述一些用于回归的方法,其中目标值 y 是输入变量 x 的线性组合。 数学概念表示为:如果  是预测值,那么有:
是预测值,那么有:

在整个模块中,我们定义向量  作为
作为 coef_ ,定义  作为
作为 intercept_ 。
如果需要使用广义线性模型进行分类,请参阅 logistic 回归 。
1.1.1. 普通最小二乘法
LinearRegression 拟合一个带有系数  的线性模型,使得数据集实际观测数据和预测数据(估计值)之间的残差平方和最小。其数学表达式为:
的线性模型,使得数据集实际观测数据和预测数据(估计值)之间的残差平方和最小。其数学表达式为:


LinearRegression 会调用 fit 方法来拟合数组 X, y,并且将线性模型的系数  存储在其成员变量
存储在其成员变量 coef_ 中:
>>> from sklearn import linear_model
>>> reg = linear_model.LinearRegression()
>>> reg.fit ([[0, 0], [1, 1], [2, 2]], [0, 1, 2])
LinearRegression(copy_X=True, fit_intercept=True, n_jobs=1, normalize=False)
>>> reg.coef_
array([ 0.5, 0.5])
然而,对于普通最小二乘的系数估计问题,其依赖于模型各项的相互独立性。当各项是相关的,且设计矩阵  的各列近似线性相关,那么,设计矩阵会趋向于奇异矩阵,这种特性导致最小二乘估计对于随机误差非常敏感,可能产生很大的方差。例如,在没有实验设计的情况下收集到的数据,这种多重共线性(multicollinearity)的情况可能真的会出现。
的各列近似线性相关,那么,设计矩阵会趋向于奇异矩阵,这种特性导致最小二乘估计对于随机误差非常敏感,可能产生很大的方差。例如,在没有实验设计的情况下收集到的数据,这种多重共线性(multicollinearity)的情况可能真的会出现。
示例:
1.1.1.1. 普通最小二乘法的复杂度
该方法使用 X 的奇异值分解来计算最小二乘解。如果 X 是一个 size 为 (n_samples, n_features) 的矩阵,设  ,则该方法的复杂度为
,则该方法的复杂度为 
1.1.2. 岭回归
Ridge 回归通过对系数的大小施加惩罚来解决 普通最小二乘法 的一些问题。 岭系数最小化的是带罚项的残差平方和,

其中,  是控制系数收缩量的复杂性参数:
是控制系数收缩量的复杂性参数:  的值越大,收缩量越大,模型对共线性的鲁棒性也更强。
的值越大,收缩量越大,模型对共线性的鲁棒性也更强。

与其他线性模型一样, Ridge 用 fit 方法完成拟合,并将模型系数 存储在其 coef_ 成员中:
>>> from sklearn import linear_model
>>> reg = linear_model.Ridge (alpha = .5)
>>> reg.fit ([[0, 0], [0, 0], [1, 1]], [0, .1, 1])
Ridge(alpha=0.5, copy_X=True, fit_intercept=True, max_iter=None,
normalize=False, random_state=None, solver='auto', tol=0.001)
>>> reg.coef_
array([ 0.34545455, 0.34545455])
>>> reg.intercept_
0.13636...
示例:
1.1.2.1. 岭回归的复杂度
这种方法与 普通最小二乘法 的复杂度是相同的.
1.1.2.2. 设置正则化参数:广义交叉验证
RidgeCV 通过内置的关于的 alpha 参数的交叉验证来实现岭回归。 该对象与 GridSearchCV 的使用方法相同,只是它默认为 Generalized Cross-Validation(广义交叉验证 GCV),这是一种有效的留一验证方法(LOO-CV):
>>> from sklearn import linear_model
>>> reg = linear_model.RidgeCV(alphas=[0.1, 1.0, 10.0])
>>> reg.fit([[0, 0], [0, 0], [1, 1]], [0, .1, 1])
RidgeCV(alphas=[0.1, 1.0, 10.0], cv=None, fit_intercept=True, scoring=None,
normalize=False)
>>> reg.alpha_
0.1
指定cv属性的值将触发(通过GridSearchCV的)交叉验证。例如,cv=10将触发10折的交叉验证,而不是广义交叉验证(GCV)。
参考资料
- “Notes on Regularized Least Squares”, Rifkin & Lippert (technical report, course slides).
1.1.3. Lasso
Lasso 是拟合稀疏系数的线性模型。 它在一些情况下是有用的,因为它倾向于使用具有较少参数值的情况,有效地减少给定解决方案所依赖变量的数量。 因此,Lasso 及其变体是压缩感知领域的基础。 在一定条件下,它可以恢复一组非零权重的精确集(见压缩感知_断层重建)。
在数学公式表达上,它由一个带有  先验的正则项的线性模型组成。 其最小化的目标函数是:
先验的正则项的线性模型组成。 其最小化的目标函数是:

lasso estimate 解决了加上罚项  的最小二乘法的最小化,其中, 是一个常数,
的最小二乘法的最小化,其中, 是一个常数,  是参数向量的 -norm 范数。
是参数向量的 -norm 范数。
Lasso 类的实现使用了 coordinate descent (坐标下降算法)来拟合系数。 查看 最小角回归 ,这是另一种方法:
>>> from sklearn import linear_model
>>> reg = linear_model.Lasso(alpha = 0.1)
>>> reg.fit([[0, 0], [1, 1]], [0, 1])
Lasso(alpha=0.1, copy_X=True, fit_intercept=True, max_iter=1000,
normalize=False, positive=False, precompute=False, random_state=None,
selection='cyclic', tol=0.0001, warm_start=False)
>>> reg.predict([[1, 1]])
array([ 0.8])
对于较简单的任务,同样有用的是函数 lasso_path 。它能够通过搜索所有可能的路径上的值来计算系数。
示例:
注意: 使用 Lasso 进行特征选择
由于 Lasso 回归产生稀疏模型,因此可以用于执行特征选择,详见 基于 L1 的特征选取 。
下面两篇参考解释了scikit-learn坐标下降算法中使用的迭代,以及用于收敛控制的对偶间隙计算的理论基础。
参考资料
- “Regularization Path For Generalized linear Models by Coordinate Descent”, Friedman, Hastie & Tibshirani, J Stat Softw, 2010 (Paper).
- “An Interior-Point Method for Large-Scale L1-Regularized Least Squares,” S. J. Kim, K. Koh, M. Lustig, S. Boyd and D. Gorinevsky, in IEEE Journal of Selected Topics in Signal Processing, 2007 (Paper)
1.1.3.1. 设置正则化参数
alpha 参数控制估计系数的稀疏度。
1.1.3.1.1. 使用交叉验证
scikit-learn 通过交叉验证来公开设置 Lasso alpha 参数的对象: LassoCV 和 LassoLarsCV。 LassoLarsCV 是基于下面将要提到的 最小角回归 算法。
对于具有许多线性回归的高维数据集, LassoCV 最常见。 然而,LassoLarsCV 在寻找 alpha参数值上更具有优势,而且如果样本数量比特征数量少得多时,通常 LassoLarsCV 比 LassoCV 要快。


1.1.3.1.2. 基于信息标准的模型选择
有多种选择时,估计器 LassoLarsIC 建议使用 Akaike information criterion (Akaike 信息判据)(AIC)或 Bayes Information criterion (贝叶斯信息判据)(BIC)。 当使用 k-fold 交叉验证时,正则化路径只计算一次而不是 k + 1 次,所以找到 α 的最优值是一种计算上更经济的替代方法。 然而,这样的判据需要对解决方案的自由度进行适当的估计,它会假设模型是正确的,对大样本(渐近结果)进行导出,即数据实际上是由该模型生成的。 当问题严重受限(比样本更多的特征)时,它们也容易崩溃。

示例:
1.1.3.1.3. 与 SVM 的正则化参数的比较
alpha 和 SVM 的正则化参数C 之间的等式关系是 alpha = 1 / C 或者 alpha = 1 / (n_samples * C)
1.1.4. 多任务 Lasso
MultiTaskLasso 是一个估计多元回归稀疏系数的线性模型: y 是一个形状为(n_samples, n_tasks) 的二维数组,其约束条件和其他回归问题(也称为任务)是一样的,都是所选的特征值。
下图比较了通过使用简单的 Lasso 或 MultiTaskLasso 得到的 W 中非零的位置。 Lasso 估计产生分散的非零值,而 MultiTaskLasso 的一整列都是非零的。


拟合 time-series model (时间序列模型),强制任何活动的功能始终处于活动状态。
示例:
在数学上,它由一个线性模型组成,以混合的  作为正则化器进行训练。目标函数最小化是:
作为正则化器进行训练。目标函数最小化是:

其中  表示 Frobenius 标准:
表示 Frobenius 标准:

并且 读取为:

MultiTaskLasso 类的实现使用了坐标下降作为拟合系数的算法。
1.1.5. 弹性网络
弹性网络 是一种使用 L1, L2 范数作为先验正则项训练的线性回归模型。 这种组合允许拟合到一个只有少量参数是非零稀疏的模型,就像 Lasso 一样,但是它仍然保持了一些类似于 Ridge 的正则性质。我们可利用 l1_ratio 参数控制 L1 和 L2 的凸组合。
弹性网络在很多特征互相联系的情况下是非常有用的。Lasso 很可能只随机考虑这些特征中的一个,而弹性网络更倾向于选择两个。
在实践中,Lasso 和 Ridge 之间权衡的一个优势是它允许在循环过程(Under rotate)中继承 Ridge 的稳定性。
在这里,最小化的目标函数是


ElasticNetCV 类可以通过交叉验证来设置参数 alpha ( ) 和 l1_ratio (  ) 。
) 。
示例:
下面两篇参考解释了scikit-learn坐标下降算法中使用的迭代,以及用于收敛控制的对偶间隙计算的理论基础。
参考资料
- “Regularization Path For Generalized linear Models by Coordinate Descent”, Friedman, Hastie & Tibshirani, J Stat Softw, 2010 (Paper).
- “An Interior-Point Method for Large-Scale L1-Regularized Least Squares,” S. J. Kim, K. Koh, M. Lustig, S. Boyd and D. Gorinevsky, in IEEE Journal of Selected Topics in Signal Processing, 2007 (Paper)
1.1.6. 多任务弹性网络
MultiTaskElasticNet 是一个对多回归问题估算稀疏参数的弹性网络: Y 是一个二维数组,形状是 (n_samples,n_tasks)。 其限制条件是和其他回归问题一样,是选择的特征,也称为 tasks 。
从数学上来说, 它包含一个混合的 先验和 先验为正则项训练的线性模型 目标函数就是最小化:

在 MultiTaskElasticNet 类中的实现采用了坐标下降法求解参数。
在 MultiTaskElasticNetCV 中可以通过交叉验证来设置参数 alpha ( ) 和 l1_ratio ( ) 。
1.1.7. 最小角回归
最小角回归 (LARS) 是对高维数据的回归算法, 由 Bradley Efron, Trevor Hastie, Iain Johnstone 和 Robert Tibshirani 开发完成。 LARS 和逐步回归很像。在每一步,它都寻找与响应最有关联的预测。当有很多预测有相同的关联时,它并不会继续利用相同的预测,而是在这些预测中找出应该等角的方向。
LARS的优点:
- 当 p >> n,该算法数值运算上非常有效。(例如当维度的数目远超点的个数)
- 它在计算上和前向选择一样快,和普通最小二乘法有相同的运算复杂度。
- 它产生了一个完整的分段线性的解决路径,在交叉验证或者其他相似的微调模型的方法上非常有用。
- 如果两个变量对响应几乎有相等的联系,则它们的系数应该有相似的增长率。因此这个算法和我们直觉 上的判断一样,而且还更加稳定。
- 它很容易修改并为其他估算器生成解,比如Lasso。
LARS 的缺点:
- 因为 LARS 是建立在循环拟合剩余变量上的,所以它对噪声非常敏感。这个问题,在 2004 年统计年鉴的文章由 Weisberg 详细讨论。
LARS 模型可以在 Lars ,或者它的底层实现 lars_path或 lars_path_gram中被使用。
1.1.8. LARS Lasso
LassoLars 是一个使用 LARS 算法的 lasso 模型,不同于基于坐标下降法的实现,它可以得到一个精确解,也就是一个关于自身参数标准化后的一个分段线性解。

>>> from sklearn import linear_model
>>> reg = linear_model.LassoLars(alpha=.1)
>>> reg.fit([[0, 0], [1, 1]], [0, 1])
LassoLars(alpha=0.1, copy_X=True, eps=..., fit_intercept=True,
fit_path=True, max_iter=500, normalize=True, positive=False,
precompute='auto', verbose=False)
>>> reg.coef_
array([0.717157..., 0. ])
示例:
- 使用LARS计算Lasso路径
Lars 算法提供了一个几乎无代价的沿着正则化参数的系数的完整路径,因此常利用函数 lars_path或 lars_path_gram来取回路径。
1.1.8.1. 数学表达式
该算法和逐步回归非常相似,但是它没有在每一步包含变量,它估计的参数是根据与 其他剩余变量的联系来增加的。
在 LARS 的解中,没有给出一个向量的结果,而是给出一条曲线,显示参数向量的 L1 范式的每个值的解。 完全的参数路径存在 coefpath 下。它的 size 是 (n_features, max_features+1)。 其中第一列通常是全 0 列。
参考资料:
- Original Algorithm is detailed in the paper Least Angle Regression by Hastie et al.
1.1.9. 正交匹配追踪法(OMP)
OrthogonalMatchingPursuit(正交匹配追踪法)和orthogonal_mp
使用了 OMP 算法近似拟合了一个带限制的线性模型,该限制影响于模型的非 0 系数(例:L0 范数)。
就像最小角回归一样,作为一个前向特征选择方法,正交匹配追踪法可以近似一个固定非 0 元素的最优向量解:

正交匹配追踪法也可以针对一个特殊的误差而不是一个特殊的非零系数的个数。可以表示为:

OMP 是基于每一步的贪心算法,其每一步元素都是与当前残差高度相关的。它跟较为简单的匹配追踪(MP)很相似,但是相比 MP 更好,在每一次迭代中,可以利用正交投影到之前选择的字典元素重新计算残差。
示例:
参考资料:
1.1.10. 贝叶斯回归
贝叶斯回归可以用于在预估阶段的参数正则化: 正则化参数的选择不是通过人为的选择,而是通过手动调节数据值来实现。
上述过程可以通过引入 无信息先验 到模型中的超参数来完成。 在 MARKDOWN_HASHeca181d570e60ba4edfe5c7ff6cf867eMARKDOWNHASH中使用的 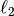 正则项相当于在 为高斯先验条件,且此先验的精确度为  时,求最大后验估计。在这里,我们没有手工调参数 lambda ,而是让他作为一个变量,通过数据中估计得到。
时,求最大后验估计。在这里,我们没有手工调参数 lambda ,而是让他作为一个变量,通过数据中估计得到。
{kind=link}
为了得到一个全概率模型,输出  也被认为是关于
也被认为是关于  的高斯分布。
的高斯分布。

Alpha 在这里也是作为一个变量,通过数据中估计得到。
贝叶斯回归有如下几个优点:
- 它能根据已有的数据进行改变。
- 它能在估计过程中引入正则项。
贝叶斯回归有如下缺点:
- 它的推断过程是非常耗时的。
参考资料
- 一个对于贝叶斯方法的很好的介绍 C. Bishop: Pattern Recognition and Machine learning
- 详细介绍原创算法的一本书 Bayesian learning for neural networks by Radford M. Neal
1.1.10.1. 贝叶斯岭回归
BayesianRidge利用概率模型估算了上述的回归问题,其先验参数

先验参数 和  一般是服从 gamma 分布 ,这个分布与高斯成共轭先验关系。 得到的模型一般称为 贝叶斯岭回归,并且这个与传统的
一般是服从 gamma 分布 ,这个分布与高斯成共轭先验关系。 得到的模型一般称为 贝叶斯岭回归,并且这个与传统的 Ridge 非常相似。
参数 , 和 是在模型拟合的时候一起被估算出来的,其中参数和通过最大似然估计得到。scikit-learn的实现是基于文献(Tipping,2001)的附录A,参数和的更新是基于文献(MacKay,1992)。
剩下的超参数 ,
, ,
, 以及
以及 是关于
是关于 和 的 gamma 分布的先验。 它们通常被选择为 无信息先验 。默认
和 的 gamma 分布的先验。 它们通常被选择为 无信息先验 。默认  。
。

贝叶斯岭回归用来解决回归问题:
>>> from sklearn import linear_model
>>> X = [[0., 0.], [1., 1.], [2., 2.], [3., 3.]]
>>> Y = [0., 1., 2., 3.]
>>> reg = linear_model.BayesianRidge()
>>> reg.fit(X, Y)
BayesianRidge(alpha_1=1e-06, alpha_2=1e-06, compute_score=False, copy_X=True,
fit_intercept=True, lambda_1=1e-06, lambda_2=1e-06, n_iter=300,
normalize=False, tol=0.001, verbose=False)
在模型训练完成后,可以用来预测新值:
>>> reg.predict ([[1, 0.]])
array([ 0.50000013])
权值 可以被这样访问:
>>> reg.coef_
array([ 0.49999993, 0.49999993])
由于贝叶斯框架的缘故,权值与 普通最小二乘法 产生的不太一样。 但是,贝叶斯岭回归对病态问题(ill-posed)的鲁棒性要更好。
示例:
参考资料
- Section 3.3 in Christopher M. Bishop: Pattern Recognition and Machine Learning, 2006
- David J. C. MacKay, Bayesian Interpolation, 1992.
- Michael E. Tipping, Sparse Bayesian Learning and the Relevance Vector Machine, 2001.
1.1.10.2. 主动相关决策理论 – ARD
ARDRegression(主动相关决策理论)和Bayesian Ridge Regression非常相似,但是会导致一个更加稀疏的权重w[1][2] 。
ARDRegression 提出了一个不同的 的先验假设。具体来说,就是弱化了高斯分布为球形的假设。
它采用 分布是与轴平行的椭圆高斯分布。
也就是说,每个权值  从一个中心在 0 点,精度为
从一个中心在 0 点,精度为  的高斯分布中采样得到的。
的高斯分布中采样得到的。

并且  .
.
与 MARKDOWNHASH860d89b8e3cc54d1782c4b65215473b8MARKDOWNHASH 不同, 每个 <img src="http://www.0dayhub.com/wp-content/uploads/img/848835d5b40c5bd74a6e592a65eed5d6.jpg" alt="w{i}" /> 都有一个标准差  。所有 的先验分布 由超参数
。所有 的先验分布 由超参数  、
、  确定的相同的 gamma 分布确定。
确定的相同的 gamma 分布确定。
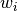{kind=link}

ARD 也被称为 稀疏贝叶斯学习 或 相关向量机 [3][4]。
示例:
参考资料:
- [1] Christopher M. Bishop: Pattern Recognition and Machine Learning, Chapter 7.2.1
- [2] David Wipf and Srikantan Nagarajan: A new view of automatic relevance determination
- [3] Michael E. Tipping: Sparse Bayesian Learning and the Relevance Vector Machine
- [4] Tristan Fletcher: Relevance Vector Machines explained
1.1.11. logistic 回归
logistic 回归,虽然名字里有 “回归” 二字,但实际上是解决分类问题的一类线性模型。在某些文献中,logistic 回归又被称作 logit 回归,maximum-entropy classification(MaxEnt,最大熵分类),或 log-linear classifier(对数线性分类器)。该模型利用函数 logistic function 将单次试验(single trial)的可能结果输出为概率。
scikit-learn 中 logistic 回归在 LogisticRegression 类中实现了二分类(binary)、一对多分类(one-vs-rest)及多项式 logistic 回归,并带有可选的 L1 和 L2 正则化。
注意,scikit-learn的逻辑回归在默认情况下使用L2正则化,这样的方式在机器学习领域是常见的,在统计分析领域是不常见的。正则化的另一优势是提升数值稳定性。scikit-learn通过将C设置为很大的值实现无正则化。
作为优化问题,带 L2罚项的二分类 logistic 回归要最小化以下代价函数(cost function):

类似地,带 L1 正则的 logistic 回归解决的是如下优化问题:

Elastic-Net正则化是L1 和 L2的组合,来使如下代价函数最小:

其中ρ控制正则化L1与正则化L2的强度(对应于l1_ratio参数)。
注意,在这个表示法中,假定目标y_i在测试时应属于集合[-1,1]。我们可以发现Elastic-Net在ρ=1时与L1罚项等价,在ρ=0时与L2罚项等价
在 LogisticRegression 类中实现了这些优化算法: liblinear, newton-cg, lbfgs, sag 和 saga。
liblinear应用了坐标下降算法(Coordinate Descent, CD),并基于 scikit-learn 内附的高性能 C++ 库 LIBLINEAR library 实现。不过 CD 算法训练的模型不是真正意义上的多分类模型,而是基于 “one-vs-rest” 思想分解了这个优化问题,为每个类别都训练了一个二元分类器。因为实现在底层使用该求解器的 LogisticRegression 实例对象表面上看是一个多元分类器。 sklearn.svm.l1_min_c 可以计算使用 L1时 C 的下界,以避免模型为空(即全部特征分量的权重为零)。
lbfgs, sag 和 newton-cg 求解器只支持 L2罚项以及无罚项,对某些高维数据收敛更快。这些求解器的参数 multi_class设为 multinomial 即可训练一个真正的多项式 logistic 回归 [5] ,其预测的概率比默认的 “one-vs-rest” 设定更为准确。
sag 求解器基于平均随机梯度下降算法(Stochastic Average Gradient descent) [6]。在大数据集上的表现更快,大数据集指样本量大且特征数多。
saga 求解器 [7] 是 sag 的一类变体,它支持非平滑(non-smooth)的 L1 正则选项 penalty="l1" 。因此对于稀疏多项式 logistic 回归 ,往往选用该求解器。saga求解器是唯一支持弹性网络正则选项的求解器。
lbfgs是一种近似于Broyden–Fletcher–Goldfarb–Shanno算法[8]的优化算法,属于准牛顿法。lbfgs求解器推荐用于较小的数据集,对于较大的数据集,它的性能会受到影响。[9]
总的来说,各求解器特点如下:
| 罚项 | liblinear |
lbfgs |
newton-cg |
sag |
saga |
|---|---|---|---|---|---|
| 多项式损失+L2罚项 | × | √ | √ | √ | √ |
| 一对剩余(One vs Rest) + L2罚项 | √ | √ | √ | √ | √ |
| 多项式损失 + L1罚项 | × | × | × | × | √ |
| 一对剩余(One vs Rest) + L1罚项 | √ | × | × | × | √ |
| 弹性网络 | × | × | × | × | √ |
| 无罚项 | × | √ | √ | √ | √ |
| 表现 | |||||
| 惩罚偏置值(差) | √ | × | × | × | × |
| 大数据集上速度快 | × | × | × | √ | √ |
| 未缩放数据集上鲁棒 | √ | √ | √ | × | × |
默认情况下,lbfgs求解器鲁棒性占优。对于大型数据集,saga求解器通常更快。对于大数据集,还可以用 SGDClassifier ,并使用对数损失(log loss)这可能更快,但需要更多的调优。
示例:
- Logistic回归中的L1罚项和稀疏系数
- L1罚项-logistic回归的路径
- 多项式和OVR的Logistic回归
- newgroups20上的多类稀疏Logistic回归
- 使用多项式Logistic回归和L1进行MNIST数据集的分类
与
liblinear的区别:当
fit_intercept=False拟合得到的coef_或者待预测的数据为零时,用solver=liblinear的LogisticRegression或LinearSVC与直接使用外部 liblinear 库预测得分会有差异。这是因为, 对于decision_function为零的样本,LogisticRegression和LinearSVC将预测为负类,而 liblinear 预测为正类。 注意,设定了fit_intercept=False,又有很多样本使得decision_function为零的模型,很可能会欠拟合,其表现往往比较差。建议您设置fit_intercept=True并增大intercept_scaling。注意:利用稀疏 logistic 回归进行特征选择
带 L1罚项的 logistic 回归 将得到稀疏模型(sparse model),相当于进行了特征选择(feature selection),详情参见 基于 L1 的特征选取。
LogisticRegressionCV 对 logistic 回归 的实现内置了交叉验证(cross-validation),可以找出最优的 C和l1_ratio参数 。newton-cg, sag, saga 和 lbfgs 在高维数据上更快,这是因为采用了热启动(warm-starting)。
参考资料:
- [5] Christopher M. Bishop: Pattern Recognition and Machine Learning, Chapter 4.3.4
- [6] Mark Schmidt, Nicolas Le Roux, and Francis Bach: Minimizing Finite Sums with the Stochastic Average Gradient.
- [7] Aaron Defazio, Francis Bach, Simon Lacoste-Julien: SAGA: A Fast Incremental Gradient Method With Support for Non-Strongly Convex Composite Objectives.
- [8] https://en.wikipedia.org/wiki/Broyden%E2%80%93Fletcher%E2%80%93Goldfarb%E2%80%93Shanno_algorithm
- [9] “Performance Evaluation of Lbfgs vs other solvers”
1.1.12. 随机梯度下降, SGD
随机梯度下降是拟合线性模型的一个简单而高效的方法。在样本量(和特征数)很大时尤为有用。 方法 partial_fit 可用于 online learning (在线学习)或基于 out-of-core learning (外存的学习)
SGDClassifier 和 SGDRegressor 分别用于拟合分类问题和回归问题的线性模型,可使用不同的(凸)损失函数,支持不同的罚项。 例如,设定 loss="log" ,则 SGDClassifier 拟合一个逻辑斯蒂回归模型,而 loss="hinge" 拟合线性支持向量机(SVM)。
参考资料
1.1.13. Perceptron(感知器)
Perceptron 是适用于大规模学习的一种简单算法。默认情况下:
- 不需要设置学习率(learning rate)。
- 不需要正则化处理。
- 仅使用错误样本更新模型。
最后一点表明使用合页损失(hinge loss)的感知机比 SGD 略快,所得模型更稀疏。
1.1.14. Passive Aggressive Algorithms(被动攻击算法)
被动攻击算法是大规模学习的一类算法。和感知机类似,它也不需要设置学习率,不过比感知机多出一个正则化参数 C 。
对于分类问题, PassiveAggressiveClassifier 可设定 loss='hinge' (PA-I)或 loss='squared_hinge' (PA-II)。对于回归问题, PassiveAggressiveRegressor 可设置 loss='epsilon_insensitive' (PA-I)或 loss='squared_epsilon_insensitive' (PA-II)。
参考资料:
- “Online Passive-Aggressive Algorithms” K. Crammer, O. Dekel, J. Keshat, S. Shalev-Shwartz, Y. Singer – JMLR 7 (2006)
1.1.15. 稳健回归(Robustness regression): 处理离群点(outliers)和模型错误
稳健回归(robust regression)特别适用于回归模型包含损坏数据(corrupt data)的情况,如离群点或模型中的错误。

1.1.15.1. 各种使用场景与相关概念
处理包含离群点的数据时牢记以下几点:
-
离群值在 X 上还是在 y 方向上?
- 离群值在 y 方向上

- 离群值在 X 方向上

-
离群点的比例 vs. 错误的量级(amplitude)
离群点的数量很重要,离群程度也同样重要。
- 低离群点的数量
- 高离群点的数量

稳健拟合(robust fitting)的一个重要概念是崩溃点(breakdown point),即拟合模型(仍准确预测)所能承受的离群值最大比例。
注意,在高维数据条件下( n_features大),一般而言很难完成稳健拟合,很可能完全不起作用。
寻找平衡: 预测器的选择
- Scikit-learn提供了三种稳健回归的预测器(estimator): RANSAC , Theil Sen 和 HuberRegressor
- HuberRegressor 一般快于 RANSAC 和 Theil Sen ,除非样本数很大,即
n_samples>>n_features。 这是因为 RANSAC 和 Theil Sen 都是基于数据的较小子集进行拟合。但使用默认参数时, Theil Sen 和 RANSAC 可能不如 HuberRegressor 鲁棒。- RANSAC 比 Theil Sen 更快,在样本数量上的伸缩性(适应性)更好。
- RANSAC 能更好地处理y方向的大值离群点(通常情况下)。
- Theil Sen 能更好地处理x方向中等大小的离群点,但在高维情况下无法保证这一特点。
实在决定不了的话,请使用 RANSAC
1.1.15.2. RANSAC: 随机抽样一致性算法(RANdom SAmple Consensus)
随机抽样一致性算法(RANdom SAmple Consensus, RANSAC)利用全体数据中局内点(inliers)的一个随机子集拟合模型。
RANSAC 是一种非确定性算法,以一定概率输出一个可能的合理结果,依赖于迭代次数(参数 max_trials)。这种算法主要解决线性或非线性回归问题,在计算机视觉摄影测绘领域尤为流行。
算法从全体样本输入中分出一个局内点集合,全体样本可能由于测量错误或对数据的假设错误而含有噪点、离群点。最终的模型仅从这个局内点集合中得出。

1.1.15.2.1. 算法细节
每轮迭代执行以下步骤:
- 从原始数据中抽样
min_samples数量的随机样本,检查数据是否合法(见is_data_valid)。 - 用一个随机子集拟合模型(
base_estimator.fit)。检查模型是否合法(见is_model_valid)。 - 计算预测模型的残差(residual),将全体数据分成局内点和离群点(
base_estimator.predict(X) - y)。绝对残差小于residual_threshold的全体数据认为是局内点。 - 若局内点样本数最大,保存当前模型为最佳模型。以免当前模型离群点数量恰好相等(而出现未定义情况),规定仅当数值大于当前最值时认为是最佳模型。
上述步骤或者迭代到最大次数( max_trials ),或者某些终止条件满足时停下(见 stop_n_inliers 和 stop_score )。最终模型由之前确定的最佳模型的局内点样本(一致性集合,consensus set)预测。
函数 is_data_valid 和 is_model_valid 可以识别出随机样本子集中的退化组合(degenerate combinations)并予以丢弃(reject)。即便不需要考虑退化情况,也会使用 is_data_valid ,因为在拟合模型之前调用它能得到更高的计算性能。
示例:
参考资料:
- https://en.wikipedia.org/wiki/RANSAC
- “Random Sample Consensus: A Paradigm for Model Fitting with Applications to Image Analysis and Automated Cartography” Martin A. Fischler and Robert C. Bolles – SRI International (1981)
- “Performance Evaluation of RANSAC Family” Sunglok Choi, Taemin Kim and Wonpil Yu – BMVC (2009)
1.1.15.3. Theil-Sen 预估器: 广义中值估计器(generalized-median-based estimator)
TheilSenRegressor 估计器:使用中位数在多个维度泛化,对多元异常值更具有鲁棒性,但问题是,随着维数的增加,估计器的准确性在迅速下降。准确性的丢失,导致在高维上的估计值比不上普通的最小二乘法。
示例:
参考资料:
1.1.15.3.1. 算法理论细节
TheilSenRegressor 在渐近效率和无偏估计方面足以媲美 Ordinary Least Squares (OLS) (普通最小二乘法(OLS))。与 OLS 不同的是, Theil-Sen 是一种非参数方法,这意味着它没有对底层数据的分布假设。由于 Theil-Sen 是基于中值的估计,它更适合于损坏的数据即离群值。 在单变量的设置中,Theil-Sen 在简单的线性回归的情况下,其崩溃点大约 29.3% ,这意味着它可以容忍任意损坏的数据高达 29.3% 。
scikit-learn 中实现的 TheilSenRegressor 是多元线性回归模型的推广 [8] ,利用了空间中值方法,它是多维中值的推广 [9] 。
关于时间复杂度和空间复杂度,Theil-Sen 的尺度根据

这使得它不适用于大量样本和特征的问题。因此,可以选择一个亚群的大小来限制时间和空间复杂度,只考虑所有可能组合的随机子集。
示例:
参考资料:
- [10] Xin Dang, Hanxiang Peng, Xueqin Wang and Heping Zhang: Theil-Sen Estimators in a Multiple Linear Regression Model. |
- [11] Kärkkäinen and S. Äyrämö: On Computation of Spatial Median for Robust Data Mining.
1.1.15.4. Huber 回归
HuberRegressor 与 Ridge 不同,因为它对于被分为异常值的样本应用了一个线性损失。如果这个样品的绝对误差小于某一阈值,样品就被分为内围值。 它不同于 TheilSenRegressor 和 RANSACRegressor ,因为它没有忽略异常值的影响,并分配给它们较小的权重。

这个 HuberRegressor 最小化的损失函数是:

其中

建议设置参数 epsilon 为 1.35 以实现 95% 统计效率。
1.1.15.5. 注意
HuberRegressor 与将损失设置为 huber的 SGDRegressor 并不相同,体现在以下方面的使用方式上。
HuberRegressor是标度不变性的. 一旦设置了epsilon, 通过不同的值向上或向下缩放X和y,就会跟以前一样对异常值产生同样的鲁棒性。相比SGDRegressor其中epsilon在X和y被缩放的时候必须再次设置。HuberRegressor应该更有效地使用在小样本数据,同时SGDRegressor需要一些训练数据的 passes 来产生一致的鲁棒性。
示例:
参考资料:
- Peter J. Huber, Elvezio M. Ronchetti: Robust Statistics, Concomitant scale estimates, pg 172
另外,这个估计是不同于 R 实现的 Robust Regression (http://www.ats.ucla.edu/stat/r/dae/rreg.htm) ,因为 R 实现加权最小二乘,权重考虑到每个样本并基于残差大于某一阈值的量。
1.1.16. 多项式回归:用基函数展开线性模型
机器学习中一种常见的模式,是使用线性模型训练数据的非线性函数。这种方法保持了一般快速的线性方法的性能,同时允许它们适应更广泛的数据范围。
例如,可以通过构造系数的 polynomial features 来扩展一个简单的线性回归。在标准线性回归的情况下,你可能有一个类似于二维数据的模型:

如果我们想把抛物面拟合成数据而不是平面,我们可以结合二阶多项式的特征,使模型看起来像这样:

观察到这 还是一个线性模型 (这有时候是令人惊讶的): 看到这个,想象创造一个新的变量
![z = [x_1, x_2, x_1 x_2, x_1^2, x_2^2]](https://i0.wp.com/www.0dayhub.com/wp-content/uploads/img/642372b631f22b9db0dc4f30d9ab67e6.jpg)
有了这些重新标记的数据,我们可以将问题写成

我们看到,所得的 polynomial regression 与我们上文所述线性模型是同一类(即关于 是线性的),因此可以用同样的方法解决。通过用这些基函数建立的高维空间中的线性拟合,该模型具有灵活性,可以适应更广泛的数据范围。
这里是一个例子,使用不同程度的多项式特征将这个想法应用于一维数据:

这个图是使用 PolynomialFeatures 预创建。该预处理器将输入数据矩阵转换为给定度的新数据矩阵。使用方法如下:
>>> from sklearn.preprocessing import PolynomialFeatures
>>> import numpy as np
>>> X = np.arange(6).reshape(3, 2)
>>> X
array([[0, 1],
[2, 3],
[4, 5]])
>>> poly = PolynomialFeatures(degree=2)
>>> poly.fit_transform(X)
array([[ 1., 0., 1., 0., 0., 1.],
[ 1., 2., 3., 4., 6., 9.],
[ 1., 4., 5., 16., 20., 25.]])
X 的特征已经从 ![[x_1, x_2]](https://i2.wp.com/www.0dayhub.com/wp-content/uploads/img/58d06eb9b8003c392af19e09ce5ab1a4.jpg) 转换到
转换到 ![[1, x_1, x_2, x_1^2, x_1 x_2, x_2^2]](https://i0.wp.com/www.0dayhub.com/wp-content/uploads/img/6b474f60cd7fcc77b4a950334fc6483f.jpg) , 并且现在可以用在任何线性模型。
, 并且现在可以用在任何线性模型。
这种预处理可以通过 Pipeline 工具进行简化。可以创建一个表示简单多项式回归的单个对象,使用方法如下所示:
>>> from sklearn.preprocessing import PolynomialFeatures
>>> from sklearn.linear_model import LinearRegression
>>> from sklearn.pipeline import Pipeline
>>> import numpy as np
>>> model = Pipeline([('poly', PolynomialFeatures(degree=3)),
... ('linear', LinearRegression(fit_intercept=False))])
>>> # fit to an order-3 polynomial data
>>> x = np.arange(5)
>>> y = 3 - 2 * x + x ** 2 - x ** 3
>>> model = model.fit(x[:, np.newaxis], y)
>>> model.named_steps['linear'].coef_
array([ 3., -2., 1., -1.])
利用多项式特征训练的线性模型能够准确地恢复输入多项式系数。
在某些情况下,没有必要包含任何单个特征的更高的幂,只需要相乘最多  个不同的特征即可,所谓 interaction features(交互特征) 。这些可通过设定
个不同的特征即可,所谓 interaction features(交互特征) 。这些可通过设定 PolynomialFeatures 的 interaction_only=True 得到。
例如,当处理布尔属性,对于所有 
 ,因此是无用的;但
,因此是无用的;但  代表两布尔结合。这样我们就可以用线性分类器解决异或问题:
代表两布尔结合。这样我们就可以用线性分类器解决异或问题:
>>> from sklearn.linear_model import Perceptron
>>> from sklearn.preprocessing import PolynomialFeatures
>>> import numpy as np
>>> X = np.array([[0, 0], [0, 1], [1, 0], [1, 1]])
>>> y = X[:, 0] ^ X[:, 1]
>>> y
array([0, 1, 1, 0])
>>> X = PolynomialFeatures(interaction_only=True).fit_transform(X).astype(int)
>>> X
array([[1, 0, 0, 0],
[1, 0, 1, 0],
[1, 1, 0, 0],
[1, 1, 1, 1]])
>>> clf = Perceptron(fit_intercept=False, max_iter=10, tol=None,
... shuffle=False).fit(X, y)
分类器的 “predictions” 是完美的:
>>> clf.predict(X)
array([0, 1, 1, 0])
>>> clf.score(X, y)
1.0